一. 数据结构和算法概述
ctrl + N—> 搜索查看源代码出现这种报错的原因是因为没有添加捕获异常的代码
快捷添加的方式,将指针移到报错位置,使用
ctrl+alt+t,选择try/catch,问题解决shift+shift搜索linklist.java
快速生成一个对象 (解决二次类型声明的冗杂代码)
- 先写右边,
ctrl+alt+v生成对象快速生成构造方法的快捷键:
- Alt + Insert 或者是 点击 Generate
Alt+ Enter自动导入包
Ctrl+alt+L格式化数组,但和QQ的快捷键冲突
1.1 数据结构简介 :
数据结构含义 : 一门研究 非数值计算的 程序设计问题中的 操作对象,以及他们之间的 关系和 操作等相关问题的学科
数据结构分类 :把数据结构分为逻辑结构和物理结构两大类
逻辑结构 :
- 从具体问题中抽象出来的模型, 是抽象意义上的结构,按照对象中 数据元素之间的 相关关系分类,分为
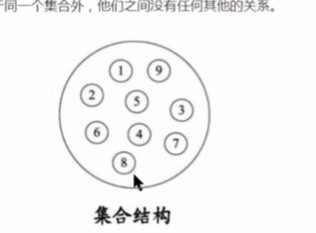
集合结构 : 集合结构中数据元素除了属于同一集合外,他们之间没有任何其他的关系
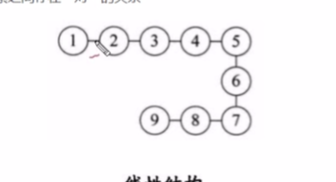
线性结构 : 线性结构中的数据元素之间存在一对一的关系
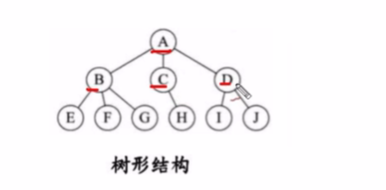
树形结构 : 树形结构中的元素之间存在一对多的层次关系
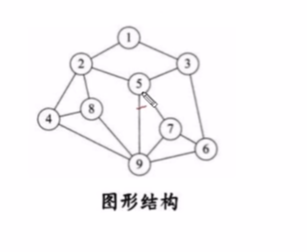
图形结构 : 图形结构的数据结构元素是多对多的关系
物理结构分类 :
逻辑结构在计算机中真正的表示方式(又称为映像)称为物理结构, 也可以叫做存储结构。
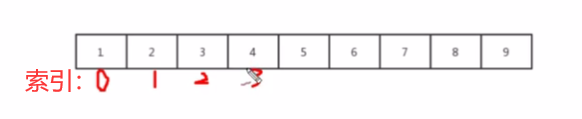
常见的物理结构 : 顺序存储结构,链式存储结构
顺序存储结构 : 把数据元素放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的,比如我们常用的数组就是顺序存储结构
链式存储结构 :
是把数据元素存放在任意的存储单元里, 这组存储单元可以是连续的也可以是不连续的。此时。
- 数据结构之间并不能反映元素间的逻辑关系。因此,在链式存储结构中引入一个指针存放数据元素的地址,这样通过地址可以找到相 关联 数据元素的位置
1-2 算法
算法是指解题方案的准确而正确的描述, 是一系列解决问题的清晰指令,算法代表着用系统的方法解决问题的策略机制,也就是说,能够对一定规范的输入,在有限时间内获得多要求的输出
- 即 : 根据一定的条件,对一些数据进行计算, 得到需要的结果
在程序中,可以用不同的算法解决相同的问题,而不同的算法的成本是不相同的。一个优秀的算法追求以下两个目标:
- 花最少的时间完成需求
- 占用最少的内存空间完成需求
1-3 算法的时间复杂度分析
事前分析估算法
在计算机程序编写前,依据统计方法对算法进行估算。经过总结,我们发现一个高级语言编写的程序在计算机上运行所消耗的时间取决于下列因素
- 算法采用的策略和方案
- 编译产生的代码质量 (XXXXXXXXXX)
- 问题的输入规模(所谓的问题输入规模就是输入量的多少)
- 机器执行指令的速度(XXXXXXXXXXX)
事后分析估算法
通过设计好的测试程序和测试数据,利用计算机计时器对不同的算法编制的程序的运行时间进行比较,从而确定算法效率的高低
- 缺陷 : 必须依据算法实现好的测试程序,通常要花费大量的时间和经历;并且不同的测试环境(硬件环境)的差别导致测试的结果差异也很大
```Java
package test;// 计算100个1 +100个2 + 100个100的结果
public class test1_3 {public static void main(String[] args) { for (int i = 1; i <= n; i++) { for (int j = 1; j <= n; j++) { sum += i; } } System.out.println("sum" + sum); }}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
- 在研究算法的效率时,只考虑核心代码的执行次数
- 研究算法复杂度,侧重的是当输入规模增大时,算法的增长量的一个抽象规律,而不是精确定位需要执行多少次,如果这样,又得重新考虑编译期优化的问题,容易主次颠倒
4. 不关心编写程序的语言是什么,不关心这些程序将跑在什么计算机上,只关心它所实现的算法.
- 不不计循环索引的递增和循环终止的条件,变量声明,打印结果等操作,最终在分析程序的运行时间时,最重要的是把程序看作独立于程序设计语言的算法或一系列步骤
- 我们分析一个算法的运行时间,最重要的是把核心操作的次数和输入规模关联起来
##### 1-4 算法时间复杂度 -- 函数渐进增长
1. 给定两个函数f(n)和g(n),如果存在一个整数N,使得对于所有的n>N , f(n)总是比g(n)大,,那么我们说f(n)的增长渐进快于g(n).
- 随着输入规模的增大,算法的常熟操作 可以忽略不记
- 随着输入规模的增大,与最高次项相乘的相乘可以忽略
- 最高次项的指数大的,随着n的增长,结果也会增长特别快
- 算法函数中n最高次幂越小, 算法效率 越高
2. 总结四个测试 :
- **算法函数中的常数可以忽略**
- **算法函数中最高次幂的常数因子可以忽略**
- **算法函数中最高次幂越小,算法效率越高**
##### 1-5 算法时间复杂度 -- 大O记法
1. - 在进行算法分析时,语句总的执行次数T(n)时关于问题规模n的函数,进而分析T(n)随着n的变化情况并确定T(n)的量级.
- 算法的时间复杂度,就是算法的时间量度,记作 :T(n) = O(f(n)).
- **算法执行时间的增长率和f(n)的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度,其中f(n)是问题规模n的某个函数**
2. **执行时间 = 执行次数**
3. 用算法O()来体现算法时间复杂度的记法, 我们称之为大O记法.随着输入规模n的增大,T(n)增长最慢的算法为最优算法
4. 推导大O阶段的表示法有 以下规则 :
- **用常数1取代运行时间中的所有加法常数;**
- **在修改后的运行次数中,只保留高阶项;**
- **如果最高阶项存在,且常数因子不为 1, 则去除与这个项相乘的常数**
规则的例子 :
```java
算法一 : 3次----------> O(1)
算法二 : n+3次 ----------> O(n)
算法三 : n^2+2次 ----------> O(n^2)
1-6 算法时间复杂度 – 常见的大O阶
线性阶 : 一般含有非嵌套循环涉及线性阶,线性阶就是随着输入规模的扩大,对应计算次数呈直线增长
- 下面的代码 : 它的循环的时间复杂度为O(n),因为循环体中的代码需要执行n次
1
2
3
4
5
6
7
8
9
10
11public class test1_1 {
// psym
public static void main(String[] args) {
int sum = 0; //执行一次
int n = 100;// 执行1次
for (int i = 1; i <= n; i++) { // 执行n+1次
sum += i;//执行n次
}
System.out.println("sum=" + sum);
}
}平方阶 : 一般嵌套循环属于这种时间复杂度
- 下面这段代码,n=100,也就是说,外层循环每执行一次,内层循环就执行100次
- 总共程序需要n的平方次循环,所以这段代码的时间复杂度就是O(n^2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15package test;
// 计算100个1 +100个2 + 100个100的结果
public class test1_3 {
public static void main(String[] args) {
int n = 1000;
int sum = 0;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
sum += i;
}
}
System.out.println("sum" + sum);
}
}立方阶 : 三层循环属于这种时间复杂度
对数阶 :
- 假设有x个2相乘后大于n,则会退出循环,由于是2*x = n,得到x=log(2)n,所以这个循环的时间复杂度为O(logn)
- 对于对数阶 ,由于随着输入规模n的增大,不管底数为多少,他们呢的增长趋势是一样的,所以我们会忽略底数
1
2
3
4int i = 1,n=100;
while(i<n){
i = i*2;
}
常数阶 :一般不涉及循环操作的都是常数阶,因为它不会随着n的增长而增加操作次数
- 时间复杂度: O(1)
1
2int n = 100;
int i = n+2;总结: 对常见时间复杂度的一个总结 :
描述 增长的数量级 说明 举例 常数级别 1 普通语句 将两个数相加 对数级别 logN 二分策略 二分查找 线性级别 N 循环 找出最大元素 线性对数级别 NlogN 分治思想 归并排序 平方级别 N^2 双层循环 检查所有元素对 立方级别 N^3 三层循环 检查所有三元组 指数级别 2^N 穷举查找 检查所有子集 复杂程度从低到高依次为 :
O(1) < O(logn) <O(n) <O(nlogn) <O(n^2) <O(n^3)
1-7 算法时间复杂度 – 函数调用的时间复杂度分析
之前我们分析的都是单个函数内,算法代码的时间复杂度,接下来我们分析函数调用过程中时间复杂度
案例一 :
1
2
3
4
5
6
7
8
9
10public static void main(String[] args){
int n = 100;
for(int i = 0; i<n; i++){
show(i);
}
private static void show(int i){
sout(i);
}
}- 在main方法中,有一个for循环,循环体调用了show方法,由于show方法内部只执行了一行代码, 所以show方法的时间复杂度 O(1),那main方法的时间复杂度就是O(n)
案例二:
show方法的时间复杂度O(n),最终main方法的时间复杂度为O(n^2)
1
2
3
4
5
6
7
8
9
10
11
12
13public static void main(String[] args) {
int n =100;
show(n);
for( int i = 0; i < n; i++){
show(i);
}
}
private static void show(int i){
for( int i = 0; i < n; i++){
sout(i);
}
}
最坏情况
有一个存储了n个随机数字的数组,请从中查找出指定的数字
1
2
3
4
5
6
7
8
9public int search(int num){
int[] arr = {11,10,9,34,24,34,0}
for(int i = 0; i < arr.length; i++){
if(num == arr[i]){
return i;
}
}
return -1;
}最好情况 : 查找的第一个数字就是期望的数字,那么算法的时间复杂度 O(1)
最坏情况 : 查找的最后一个数字,才是期望的数字,那么算法的时间复杂度为O(n)
平均情况 :任何数字查找的平均成本是O(n/2)
1-8 算法的空间复杂度分析 – Java中常见内存占用
基本数据类型内存占用情况 :
数据类型 内存占用字节数 byte 1 short 2 int 4 long 8 float 4 double 8 boolean 1 char 2 计算机访问的方式都是一次一个字节
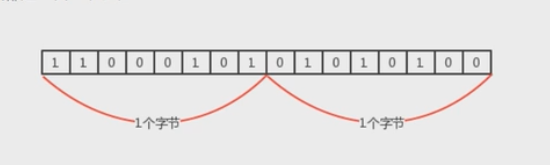
一个引用(机器地址)需要8个字节表示 :
例如: Date date = new Date(), 则date这个变量需要占用8个字节来表示
创建一个对象,比如new Date(), 除了Date对象内部存储的数据占用的内存,该对象本身也有内存开销,每个对象的自身开销是16个字节, 用来保存对象的头信息
一般内存的使用,如果不够8个字节,都会被自动填充为8字节 :
1
2
3
4
5
6
7public class A{
public int a = 1;
}
通过new A()创建一个对象的内存占用如下:
1. 整形成员变量a占用4个字节
2. 对象本身占用16个字节
那么创建该对象总共需要20个字节,但由于不是以8位单位,会自动填充为24个字节java中数组被限定为对象,他们一般都为记录长度而需要额外的内存,一个原始数据类型的数组一般需要24字节的头信息(16个个自己的对象开销,4字节用于保存长度以及4个填充字节)再加上保存值所需的内存
1-9 算法的空间复杂度
第二章 排序
- 冒泡,选择,插入排序最坏情况下的时间复杂度为O(N^2)
- 后面是高级排序
2-1 Compareble接口
简单排序 :在java的开发工具包jdk中, 给我们提供了 很多数据结构和算法的实现, 比如List , Set ,Map , Math等等, 都是以API的方式提供,
- 借助jdk的方式,将算法封装到某个类中,在我们写java代码之前,就要进行API的设计,随后进行API的实现
设计一套API如下 :
类名 ArrayList 构造方法 Array List() : 创建ArrayList对象 成员方法 1. boolean add( E e) : 向集合中添加元素
2. E remove(int index) : 从集合中删除指定的元素由于要讲排序,会在元素之间进行比较,而java提供一个接口Comparable就是用来定义排序规则的
- 需求 :
- 定义一个学生类Student, 具有年龄age 和姓名 username 两个属性, 并通过Compareble接口提供比较规则
- 定义测试类Test,在测试类中定义测试方法Comparable getMax(Comparable c1,Comparable c2)完成测试
- 需求 :
不只对数据进行排序,对所有实现了Comparable接口的对象进行排序
2-2 冒泡排序
让最大的元素冒到后面去
冒泡排序API设计 :
类名 Bubble 构造方法 Bubble() : 创建Bubble对象 成员方法 1. public static void sort(Comparable[] a) : 对数组内的元素进行排序
2. private static boolean greater(Comparable v,Comparable w) : 判断v是否大于w
3. private static exch (Comparable[] a,int i,int j) : 交换a数组,索引i和索引j处的值冒泡排序的时间复杂度分析 :
使用了双层for循环,其中内层循环的循环体是真正完成排序后的代码,我们分析冒泡排序的时间复杂度,主要分析内层循环体的执行次数即可
最坏情况下,也就是假如要排序的元素为{6,5,4,3,2,1}逆序,那么 :
元素比较的次数为:
(N-1)+(N-2)+…+1 = ((N-1)+1)*(N-1)/2 = N^2/2-N/2;
元素交换的次数 :
(N-1)+….+1 = 同上
总执行次数 :
(N^2/2 - N/2)+(N^2/2-N/2)=N(N-1)

2-3 选择排序
选出最小的元素放在前面
每一次遍历的过程中,都假定第一个索引处的元素是min,和其他索引处的值依次比较,最后得到min所在的索引
选择排序API
类名 Selection 构造方法 Selection() : 创建Selection对象 成员方法 1. public static void sort(Comparable[] a) : 对数组内的元素进行排序
2. private static boolean greater(Comparable v, Comparable w): 判断v是否大于w
3. private static void exch(Comparable[] a,int i ,int j) :交换a数组中索引i和索引j处得值选择排序的时间复杂度分析 ;
使用双层for循环,其中外层循环完成了数据交换,内层循环完成了数据比较,分别统计数据交换次数和数据比较次数
数据比较次数 :
(N-1)+(N-2)…+1=N(N-1)/2
数据交换次数 :
N-1
时间复杂度:N(N-1)/2+N-1
根据大O推导法则,保留最高阶项,去除常数因子,时间复杂度为O(N^2)
2-4 插入排序(Insertion sort)

插入排序的工作方式是一种简单直观且稳定的排序算法
- 把所有的元素分为两组,已经排序的和未排序的
- 找到未排序的组中的第一个元素,向已经排序组中进行插入
- 倒叙遍历已经排序的元素,依次和待插入的元素进行比较,直到找到一个元素小于等于待插入元素,那么就把待插入的元素放到这个位置,其他的元素向后移动一位
插入排序API设计 :
类名 Insertion Insertion():创建Insertion对象 1. public static void sort(Comparable[] a):对数组内的元素进行排序
2. privte static boolean greater(Comparable v,Comparable w): 判断v是否大于w
3. private static void exch(Comparable[] a,int i,int j): 交换a数组中索引i和索引j处的值插入排序的时间复杂度分析:(最坏情况)
- 待排序的数组元素 {12,10,6,5,4,3,2,1}
- 比较的次数: (N-1)+(N-2)+…1
- 交换的次数: 同上
- 执行的总次数:N*2-N
—————-> 大O推导法: O(n*2)
2-5 希尔排序(Shell缩小增量排序)
希尔排序是插入排序的一种,又称为“缩小增量排序”,是插入排序算法的一种更高效的改进版本
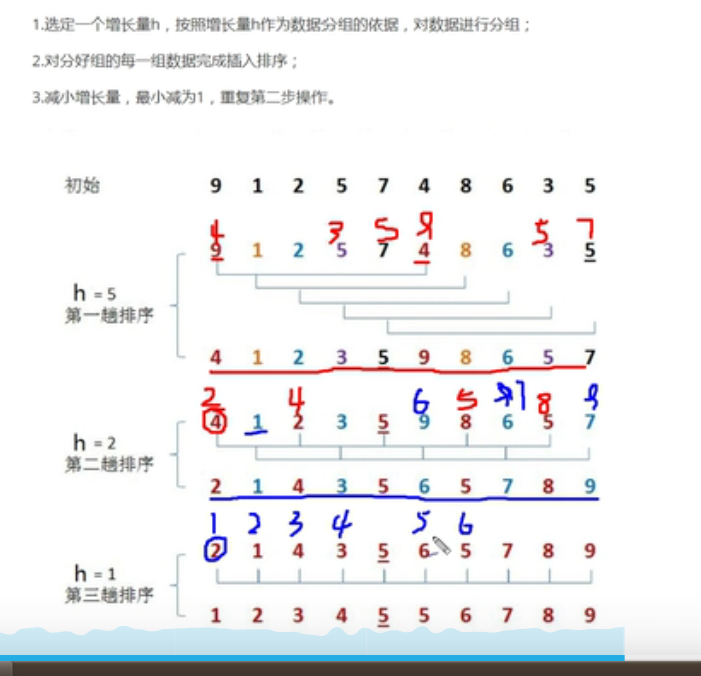
排序原理 :
- 选定一个增长量,按照增长量h作为数据分组的依据,对数组进行分组
- 对分好组的每一组数据完成插入排序
- 减小增长量,最小减为1,重复第二步操作
增长量h的确定 : 增长量h的值每一固定的规则,采取以下规则:
1
2
3
4
5
6
7int h = 1;
while(h < 数组的长度/2){
h = 2h+1; //3,7
}
// 循环结束后我们就可以确定h的最大值
h的减小规则为 :
h = h/2 // 7/2=3 ; 3/2=1
2-5-1 希尔排序的API设计
类名 Shell 构造方法 Shell():创建Shell对象 成员方法 1. public static void(Comprable[] a): 对数组的元素进行排序
2.private static boolean greater(Comparable v, Comprable w):判断v是否大于w
3.private static void exch(Commparable[] a, int i,int j): 交换a数组中,索引i和索引j处的值
2-5-2希尔排序的时间复杂度分析
- 事后分析法对希尔排序进行时间复杂度的分析
插入排序和希尔排序不会比较
2-6 归并排序(这是第四五遍,我懂了!!!离打谱事件!)
2-6-1 归并排序–递归(StackFlowOver)
递归算法—-定义方法时,在方法内部调用方法本身,称之为递归
1
2
3
4public void show(){
sout("aaa");
show();
}作用:通常把一个大型复杂的问题,层层转换为一个与原问题相似的,规模较小的问题来求解。递归只需要少量的程序就可以描述出接替过程所需要的多次重复计算,大大减少了程序的代码量
注意事项 : 在递归中,不能无限制的调用自己,必须要有边界条件,能够让递归结束,因为每一次递归调用都会在栈内存开辟新的空间
- 重复执行方法,如果递归的层级太深,很容易造成栈内存溢出
定义一个方法,使用递归完成求N的阶乘 :
1
2
3
4
5
6
7
8分析:
1!: 1
2!: 2*1=2*1!
3!: 3*2*1=3*2!
...
n!: n*(n-1)*(n-2)*...*2*1 = n*(n-1)!
// 所以,假设有一个方法factorial(n)用来求n的阶乘,那么n的阶乘还可以表示为n*factorial(n-1)```js
package test.test_child;public class Testfactorial {
public static void main(String[] args) { // 求N的阶乘 long result = factorial(5); System.out.println(result); } // 求n的阶乘 public static long factorial(int n){ if (n==1){ //结束条件 return 1; } return n*factorial(n-1); }}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
##### 2-6-2 归并排序【分治思想】
1. 归并排序是在建立在操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;
- 即先使每个子序列有序,再使子序列段间有序。
- 若将两个有序表合并成一个有序表,称为二路归并。
2. 排序原理 :
- 尽可能的一组数据拆分成两个元素相等的子组并对每一个子组继续拆分,直到拆分后的每个子组的元素个数是1为止
- 将相邻的两个子组进行合并成一个有序的大组
- 不断的重复步骤2,直到最终只有一个组为止。
- 
3. 归并排序API设计
| 类名 | Merge |
| -------- | ------------------------------------------------------------ |
| 构造方法 | Merge():创建Merge对象 |
| 成员方法 | 1. public static void sort(Comparable[] a):对数组内的元素进行排序<br />2. private static void sort(Comparable[] a,int Io,int hi) : 对数组a中从索引lo到索引hi之间的元素进行排序<br />3. private static void merge(Comparable[] a,int lo, int mid, int hi): 从索引lo到索引mid为一个子组, 从索引mid+1到索引hi为另一个子组,把数组a中的这两个子组的数据合并成一个有序的大组(从索引lo到索引hi)<br />4. private static boolean less(Comparable w): 判断v是否小于w<br />5. private static void exch(Comparable[] a,int t,int j): 交换a数组中,索引i和索引j处的值 |
| 成员变量 | private static void Comparable[] assist : 完成归并操作需要的辅助数组 |
4. 
##### 2-6-3 归并排序的时间复杂度进行分析
1. 思想:
- 分治思想,通过递归调用将他们进行单独排序,最后将有序的子数组归并为最终的排序结果。
- 该递归的出口在于如果一个数组不能在被分为两个子数组,那么就会执行merge归并,在归并的时候判断元素的大小进行排序
2. 
- 用树状图来描述归并,如果一个数组有8个元素,那么它将每次除以2找到最小的子数组,共拆log8次值为3;
- 所以树共有三层,那么自顶向下第k层有2^k个子数组,每个数组的长度为2^(3-k),归并最多需要2^(3-k)次比较
- 因此每层的比较次数为2^k*2^(3-k) = 2^3
- 那么3层总共为3*2^3
3. 时间复杂度的算法:
- 假设元素的个数为n,呢么使用归并排序拆分的次数为log2(n),所以共log2(n)层,那么使用log2(n)替换上面3*2^3中的3这个层数,
- 最终得出的归并排序的时间复杂度为:log2(n)*2^(log2(n)) = log2(n)*n,根据大O推导法则,忽略底数,最终归并排序的时间复杂度为**O(nlogn)**;
4. 归并排序的缺点
- 需要申请额外的数组,导致空间复杂度提升,是典型的以空间换时间的操作
5. 归并排序的与希尔排序的的性能是由于插入排序的
- 希尔排序和归并排序的性能测试 :
- 这里没有去写,我好累呀!!!开玩笑
#### 2-7 归并排序和希尔排序
> 稳定性和
### 2-7 快速排序
##### 2-7-1 快速排序1
1. 简介 :
- 快速排序是对冒泡排序的一种改进
- 基本思想: 通过一趟排序将要排序的数据分隔为独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小
- 再按照此方法对这两部分数据继续快速排序
- 整个排序过程可以递归进行,依次达到整个数据变成有序序列
2. 排序原理 :
- 首先设定一个分界值,通过该分界值将数组分为左右两个部分
- 将大于或等于分界值得数据放到数组右边,小于分界值得数据放到数组的左边,此时左边部分中各元素都小于或等于分界值
- 然后,左边和右边的数据可以独立排序,对于左右两侧的数组数据可以取一个分界值,重复第二部操作
- 重复上述操作,这是一个递归定义。
##### 2-7-2 快速排序API设计
1. | 类名 | Quick |
| -------- | ------------------------------------------------------------ |
| 构造方法 | Quick{}:创建Quick对象 |
| 成员方法 | 1. public static void sort(Comparable[] a) : 对数组内的元素进行排序<br />2. private static void sort(Comparable[] a,int lo,int hi) : 对数组a中从索引lo到索引hi之间的元素进行排序<br />3. public static boolean less(Comparable x,Comparable w): 判断v是否小于w<br />4. private static int partition(Comparable []a,int lo,int hi): 对数组a中,从索引lo到索引hi之间的元素进行分组,并返回分组界限对应的索引<br />5. private static void exch(Comparable[] a,int i,int j): 交换a数组中,索引i和索引j处的值 |
2. 把一个数组切分成两个子数组的基本思想:
- 找一个基准值,用两个指针分别指向数组的头部和尾部
- 先从尾部向头部开始搜索一个基准值小的元素,搜索到即停止,并记录指针的位置
- 再从头部开始向尾部开始搜索一个比基准值大的元素,搜索到即通知,并记录指针的位置
- 交换当前左边指针位置和右边指针位置的元素
- 重复2,3,4步骤,直到左边指针的值大于右边指针的值停止
##### 2-7-3 快速排序和归并排序:
1. 分治思想: 快+归
- 归并排序将数组分为两个子数组分别排序,并将有序的组数组归并从而将整个数组排序
- 快速排序是当两个数组都有序时,整个数组自然就有序了
2. 快速排序时间复杂度分析:
- 快速排序的一次切分从两头开始交替搜索,直到left和right重合,因此,一次切分算法的时间复杂度为O(n),但整个快速排序的时间复杂度和切分的次数相关
- 最优情况 : 每一次切分选择的基准数字刚好将当前序列等分,O(nlogn);

- 最坏情况: 每一次切分选择的基准数字是当前序列中最大数或者 最小数,这使得每次切分都会有一个子组,总共切分n次,最坏情况下,快速排序的时间复杂度为O(n^2)

- 平均情况: 每一次切分选择的基准数字不是最大值也不是最小值,也不是中值,时间复杂度为O(nlogn)
##### 2-8 排序的稳定性
1. 数组arr中有若干元素,其中A元素和B元素相等,并且A元素在B元素前面,如果使用某种排序算法排序后,能够保证A元素依旧在B元素的前面,可以说这个该算法是稳定的
2. 稳定性的意义: 如果一个数据只需要一次排序,则稳定性一般没有意义;如果一组数据需要多次排序,稳定性是有意义的
- 例如要排序的内容是一组商品对象,第一次排序按照价格有低到高排序;
- 第二次排序按照销量由高到低排序,如果第二次排序使用稳定性算法,就可以使得相同销量的对象依旧保持价格高低的顺序展现,
- 只有销量不同得对象才需要重新排序,这样就可以保持第一次排序得原有意义,而且可以减少系统开销
3. 分析各个排序:
- 冒泡排序: 只有当arr[j]>arr[j+1]时,才会交换元素的位置。**稳定**
- 选择排序: **不稳定**
- 希尔排序:**不稳定**
- 归并:**稳定**
- 快速:**不稳定**
## 第三章 线性表
### 3-1 线性表
1. 线性表是最基本,最简单,也是最常用的一种数据结构;一个线性表是n个具有相同特性的数据元素的有限序列
2. - 前驱元素 : 若A元素在B元素的前面,则称为A为B的前驱元素
- 后继元素 : 若B元素在A元素的后面,则称称为B为A的后继元素
3. 线性表的特征 : 数据元素之间具有“一对一”的逻辑关系
- 第一个数据元素没有前缀,这个数据被称为**头节点**
- 最后一个数据元素没有后继,这个数据元素称为**尾节点**
4. 
5. 线性表分类 :
- 线性表中数据存储的方式可以是顺序存储,也可以是链式存储
- 按照数据的存储方式不同,则可以把线性表分为顺序表和链表
### 3-2 顺序表
##### 3-2-1 顺序表的实现
1. - 顺序表是在计算机内存中以数组的形式保存的线性表,
- 线性表的顺序存储是指用一组地址连续的存储单元,依次存储线性表中的各个元素,使得线性表中在逻辑 结构上响铃的 数据元素 存储在 相邻的物理存储单元中,
- 即通过数据元素物理存储的相邻关系 来反映数据元素之间逻辑上的相邻关系
2. 顺序表API设计 :
| 类名 | SequenceList |
| -------- | ------------------------------------------------------------ |
| 构造方法 | SequenceList(int capacity) : 创建容量为capacity的SequenceList对象 |
| 成员方法 | 1. public void clear() : 空置线性表<br />2. public boolean isEmpty() : 判断线性表是否为空, 是返回true,否则返回false<br />3. public int length() : 获取线性表中元素的个数<br />4. public T get(int i) : 获取并返回线性表中第i个元素的值<br />5. public void insert(int i, T t) : 在线性表中的第i个元素之前插入一个值为t的数据元素<br />6. public void insert(T t) : 向线性表中添加一个元素t<br />7. public T remove(int i):删除并返回线性表中第i个数据元素<br />8. public int indexOf(T t) : 返回线性表中首次出现的指定的数据元素的位序号,若不存在,则返回-1 |
| 成员变量 | 1. private T[] eles : 存储元素的数组<br />2. private int N : 当前线性表的长度 |
3. 顺序表的遍历
- 一般作为容器存储数据,都需要向外部提供遍历的方式,因此我们需要给顺序表提供遍历方式
- 在java中, 遍历结合的方式一般都是用 foreach 循环,如果让我们的SequenceList 支持 foreach 循环,需要做以下操作 :
- 让SequenceList 实现 iterable 接口, 重写iterator(方法
- 在SequenceList 内部提供了 一个内部类SIterator, 实现Iterator 接口,重写hasNext方法和next方法
4. 顺序表的容量可变
我们使用SequenceList时, 先new SequenceList(5)创建一个对对象,创建对象就需要指定容器的大小,初始化指定大小的数组来存储元素。
**这种设计不符合容器的设计理念,我们在设计顺序表时,应该考虑容器的伸缩性**
- 添加元素,应该检查当前数组的大小是否能容忍新的元素,如果不能容忍,则需要创建新的容量更大的数组,需要创建一个是原数组**两倍容量**的新数组存储元素
- 移除元素,应该检查当前数组的大小是否太大,应该创建一个容量更小的数组存储元素。数据元素的数量不足数组容量的1/4,则创建一个是原数组容量的1/2的新数组存储元素
##### 3-2-2 顺序表的时间复杂度
1. - get(i) : 只需要依次eles[i]就可以获取对应的元素,时间复杂度为`O(1)`
- insert(int i,T t) :每一次插入,都需要把i位置后面的元素移动一次,随着元素数量N的增大,移动的元素也越多,时间复杂为`O(n)`
- remove(int i) :同insert()
2. 由于顺序表的底层有数组实现, 数组的长度是固定的,所以操作时涉及了容器扩容操作(申请内存重建数组),会导致顺序表在使用过程中的时间复杂度不是线性的,在某些需要扩容的节点处,耗时会突增
##### 3-2-3 java中ArrayList实现(顺序表)
1. **java中ArrayList集合的底层也是一种顺序表**,使用数组实现,同样提供了增删改查以及扩容等功能
- 是否使用数组实现
- 有没有扩容操作
- 有没有提供遍历方式
### 3-3 链表
> 顺序表的查询很快,时间复杂度为O(1),但是增删的效率很低,每次增删操作都伴随着大量数据元素移动
##### 3-3-1 链式存储结构
1. 链表是一种物理存储单元上非连续、非顺序的存储结构,其物理结构不能只表示数据元素的逻辑结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
- 链表由一系列的结点(链表中的每一个元素称为结点)组成,结点可以在运行时动态生成
2. 如何使用链表 :
- 可以设计一个类,来描述结点这个事物,用一个属性描述这个结点存储的元素,用来另外一个属性描述这个节点的下一个结点
3. 结点API设计
| 类名 | Node<T> |
| -------- | -------------------------------------------------- |
| 构造方法 | Node( T t, Node next) : 创建Node对象 |
| 成员变量 | T item : 存储数据<br />Node next : 指向下一个节点 |
| | |
4. - 结点类实现 :
```js
public class Node<T>{
//存储元素
public T item;
// 指向下一个结点
public Node next;
public Node(T item, Node next){
this.item = item;
this.next = next;
}
}生成链表 :
1
2
3
4
5
6
7public static void main(String[] args) throw Exception{
//构造结点
Node<Integer> first = new Node<Integer>(11,null);
Node<Integer> second = new Node<Integer>(11,null);
Node<Integer> third = new Node<Integer>(11,null);
Node<Integer> fourth = new Node<Integer>(11,null);
}
3-3-2 单向列表
- 单向链表由多个结点组成,每个结点都有一个数据域和一个指针域组成
- 数据域用来存储数据
- 指针域用来指向其他后继结点
- 链表的头结点的数据域不存储数据,指针域指向第一个真正存储数据的结点

单向链表API设计
类名 LinkList 构造方法 LinkLsit() : 创建LinkList对象 成员方法 1. public void clear() : 空置线性表
2. public boolean isEmpty(): 判断线性表是否为空,true或false
3. public int length() : 获取线性表中元素的个数
4. public T get(int i) : 读取并返回线性表中的第i个元素的值
5. public void insert(T t) : 往线性表中添加一个元素
6. public void insert(int i.T t): 王线性表的第i个元素之前插入一个值为t的数据元素
7. public T remove(int i) : 删除并返回线性表中第i个数据元素
8. public int indexOf(T t) : 返回线性表中首次出现的指定的数据元素的位序号,若不存在,则返回-1
9. public T getFirst(): 获取第一个元素
10 public T getLast(): 获取最后一个元素成员内部类 private class Node : 结点类 成员变量
1. private Node first : 记录首结点
2. private Node last : 记录尾结点
2. private int N: 记录链表的长度
3-3-3 双向链表【程序第二遍写的时候有bug,第三遍搞定】
双向链表也叫双向表,是链表的一种,由多个结点组成,每个结点都由一个数据域和两个指针域组成,
- 数据域用来存储数据,其中一个指针域用来指向其后继结点,另一个指针域用来指向前驱结点。
- 链表的头结点的数据域不存储数据,指向前驱结点的指针域值为null,指向后继结点的指针域指向第一个真正存储数据的结点

按照面向对象的思想,需要设计一个类,来描述结点这个事物
- 由于结点是属于链表的,所以我们把结点类作为链表类的一个内部类来实现
结合API设计
类名 Node 构造方法 Node(T t,Node pre,Node next()) : 创建Node对象 成员变量 T item:存储数据
Node next: 指向下一个结点
Node pre:指向上一个结点双向链表API设计 :
类名 TowWayLinkList 构造方法 TowWayLink(): 创建TowWayLinkLink对象 成员方法 1. public void clear() : 空置线性表
2. public boolean isEmpty(): 判断线性表是否为空,true或false
3. public int length() : 获取线性表中元素的个数
4. public T get(int i) : 读取并返回线性表中的第i个元素的值
5. public void insert(T t) : 往线性表中添加一个元素
6. public void insert(int i.T t): 王线性表的第i个元素之前插入一个值为t的数据元素
7. public T remove(int i) : 删除并返回线性表中第i个数据元素
8. public int indexOf(T t) : 返回线性表中首次出现的指定的数据元素的位序号,若不存在,则返回-1成员内部类 private Node first : 记录首结点 成员变量 1.private Node first: 记录首结点
2.private Node last: 记录尾结点
3.private int N: 记录
3-3-4 java中的LinkList实现
java中的LinkList集合也是使用双向链表实现,并提供了增删改查等
底层是否用双向链表实现
节点类是否有三个域 : 两个指针域和一个数据域
3-3-5 链表的复杂度分析
get int(i): 每一次查询, 都需要从链表的头部开始,依次向后查找,随着数据元素N的增多,比较的元素越多,时间复杂度为O(n)insert(int i, T t):每一次插入,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n)- remove(int i): 每一次移除,需要先找到i位置的前一个元素。然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n)
- 相比较顺序表,链表插入和删除的时间复杂度虽然一样,但仍然又很大的优势,因为链表的物理地址是不连续的,它不需要预先指定存储空间大小,或者在存储过程中涉及到扩容等操作,同时它并没有涉及的元素的交换
- 相比较顺序表,链表的查询操作性能会比较低
- so,查询操作多,使用顺序表
- 增删操作多,使用链表
3-3-6 链表反转【我就是看不懂代码;again好点了;】
单链表的反转,是面试中的一个高频题目
需求:
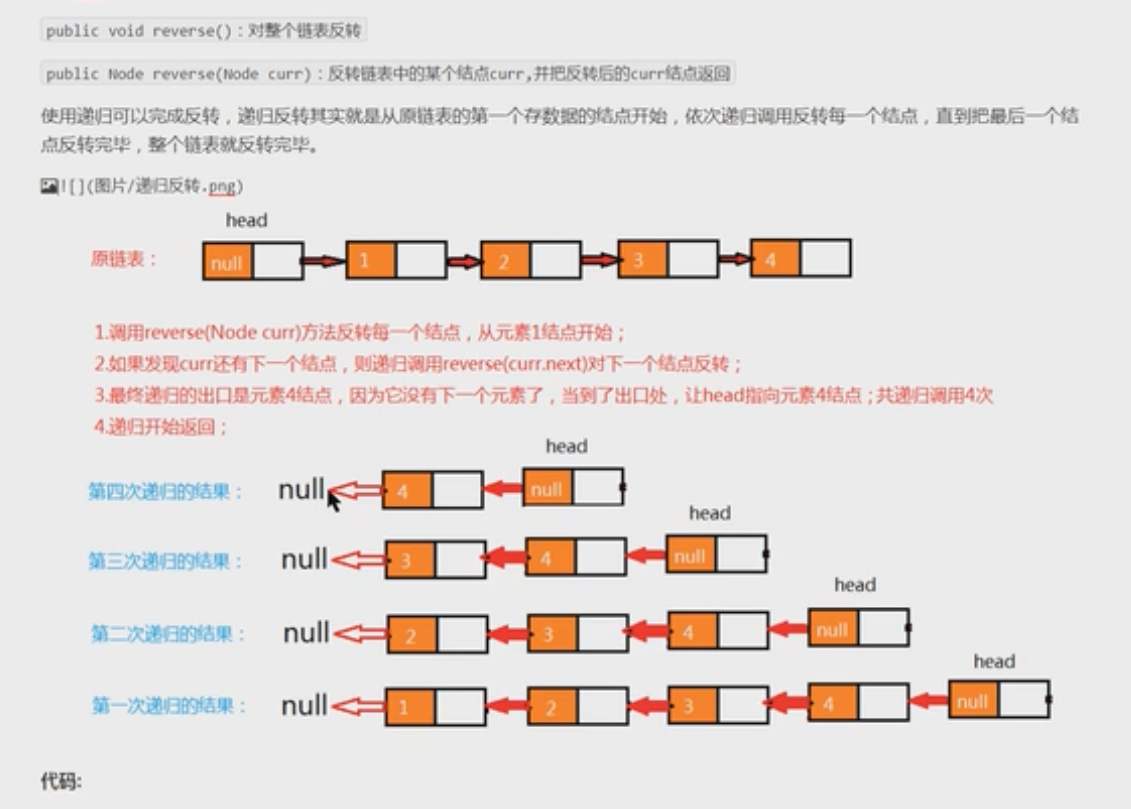
- 原链表中数据为: 1->2->3->4
- 反转后链表中的数据为: 4
- 使用递归可以完成反转,递归反转其实就是从原链表的第一个存数据的结点开始,依次递归调用反转每一个结点,直到把最后一个节点反转完毕,整个链表就反转完毕
- 调用reverse(Node curr)方法反转每一个结点,从元素1结点开始
- 如果发现curr还有下一个结点,则递归调用reverse(curr.next)对下一个结点反转
- 最终递归的出口是元素4结点,因为他没有下一个元素了,当到了出口处,让head指向元素4结点;共递归调用4
- 递归开始返回
3-4 快慢指针
3-4-1 中间值问题【没有跟着桥案例;第三遍敲了但是有bug,againok了,不是很明白;】
- 查找中间值:
- 最开始,slow和fast指针都指向链表第一个指针,然后slow每次移动一个指针,fast每次移动两个指针
- 单向链表是否有环
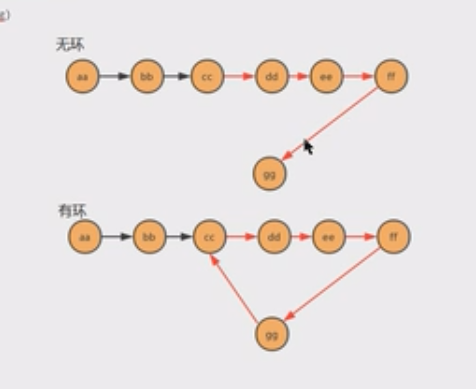
- 有环指针中快慢指针会相遇,指向同一结点
- 当快慢指针相遇时,我i们可以判断到链表有环,这是重新设定一个新指针指向链表的起点,且步长与慢指针一样,则满指针与新指针相遇的地方就是环的入口,
3-4-2 单链表是否有环问题【MyThird有问题,而且不是很懂;】
快慢指针指向有环无环问题
3-4-3 有环链表入口问题
3-5 循环链表
3-5-1 循环链表
最后一个指针的指针域指向第一个结点
循环链表的构建:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class FastSlowTest {
public static void main(String[] args) throws Exception{
// 创建结点
Node<String> first = new Node<String>("aa", null);
Node<String> second = new Node<String>("bb", null);
Node<String> third = new Node<String>("cc", null);
Node<String> fourth = new Node<String>("dd", null);
Node<String> fifth = new Node<String>("ee", null);
Node<String> six = new Node<String>("ff", null);
Node<String> seven = new Node<String>("gg", null);
// 完成结点之间的指向
first.next = second;
second.next = third;
third.next = fourth;
fourth.next = fifth;
fifth.next = six;
six.next = seven;
// 构建循环链表,让最后一个结点指向第一个结点
}
}
3-5-2 约瑟夫问题—循环链表【MyThird】
- 问题转换:
- 41个人做一圈,第一个人编号为1,第二个人编号为2
- 编号为3的人推出圈
- 自推出的那个人开始的下一个人再次从1开始报数,以此类推
- 求出最后推出的那个人的编号
- 构建思路:
- 构建含有41个结点的单向循环列表,分别存储1-41 的值,分别代表41个人
- 使用计数器count,记录当前报数的值
- 遍历链表,每循环依次,count++
- 判断count的值,如果是3,则从链表中删除这个结点并打印结点的值,把count重置为0
- 约瑟夫将朋友和自己安排在第16个和第31个位置
3-4 栈
3-4-1 概述
生活中的栈 引入到计算机中, 就是提供数据休息的地方; 数据可以进入栈中,也可以从栈中出去
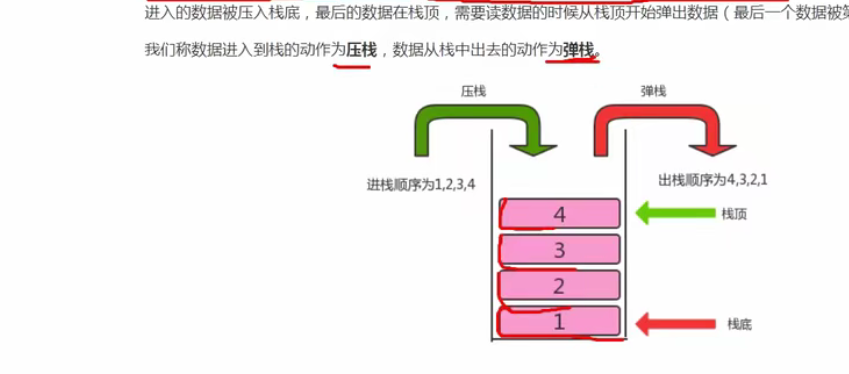
栈是一种基于先进后出(FILO)的数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。
按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出)
我们称数据进入到栈的动作是压栈,数据从栈中出去的动作为弹栈
3-4-2 栈的代码实现【数组和链表都可以实现栈】
栈API设计
类名 Stack 构造方法 Stack: 创建Stack对象 成员方法 1. public boolean isEmpty(): 判断栈是否为空,是返回true,否返回false
2. public int size(): 获取栈中元素的个数
3. public T pop(): 弹出栈顶元素
4. public void push(T t): 向栈中压入元素t成员变量 1. private Node head: 记录首结点
2. private int N: 当前栈的元素个数成员内部类 private class Node: 节点类
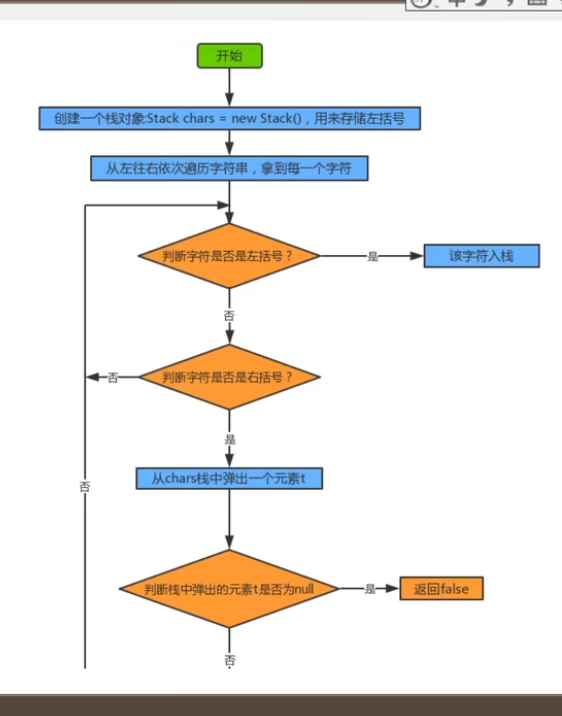
3-4-3 括号匹配问题1【Mythird有问题,而且我没有看懂;】
给定一个字符串,里边包含”()”小括号和其他字符,请编写检查该字符串的小括号是否成对出现
1
2
3
4
5
6例如:
"(上海)(长安)": 是否匹配
"上海((长安))": 正确匹配
“上海(长安(北京)(深圳)南京)”: 正确匹配
“上海(长安))”: 错误匹配
“((上海)长安”: 错误匹配示例代码:
3-8 逆波兰表达式
2-8-1 逆波兰表达式求值问题
- 中缀表达式:
- 中缀表达式的特点: 二元运算符总是置于两个操作数中间
- 中缀表达式对于计算机来说: 运算顺序不由规律性,不同的运算符有不同的优先级。
- 计算机执行中缀表达式,需要解析表达式语义,做大量的优先级相关操作
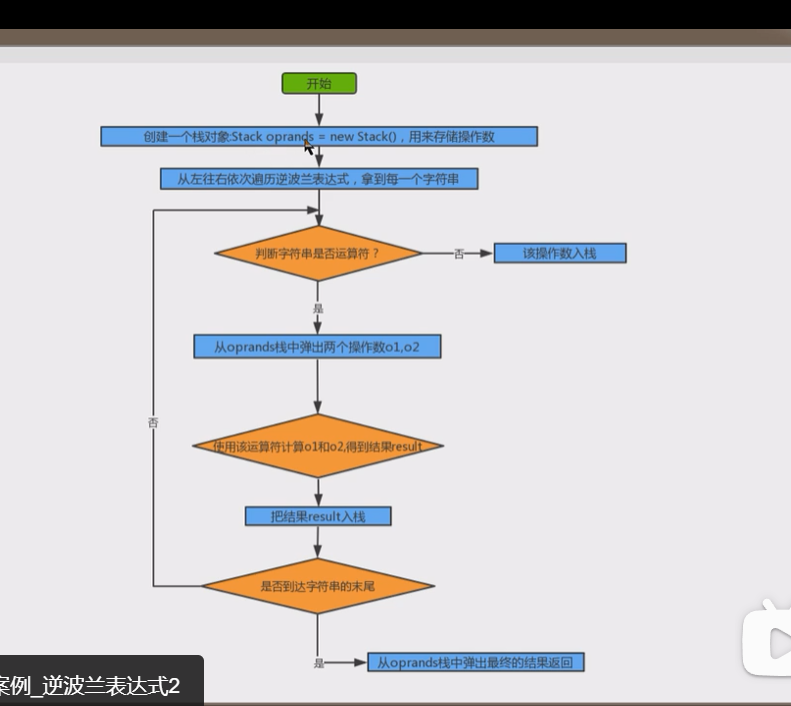
- 逆波兰表达式(后缀表达式):
- 运算符总是放在跟他相关的操作数之后

2-8-2 逆波兰表达式的实现
2-8-3 【MyThird的实现有bug,看不懂;】
3-5 队列
队列是一种基于先进先出(FIFO)的数据结构,是一种只能在一端进行插入,在另一端进行删除操作的特殊线性表,它代表先进先出的原则存储数据,先进入的数据,在读取数据时先读被读出来
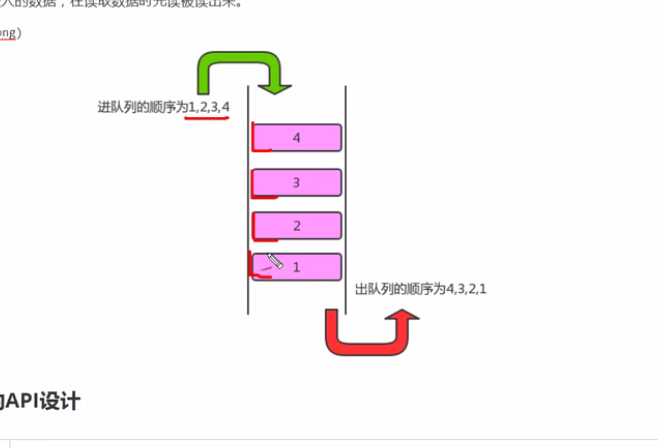
3-5-2 队列的API设计和实现
类名 Queue 构造方法 Queue():创建Queue对象 成员方法 1. public boolean isEmpty(): 判断队列是否为空,是返回true,否返回 false
2. public int size(): 获取队列中元素的个数
3. public T dequeue(): 从队列中拿出一个元素
4. publilc void enqueue(T t): 往队列中 插入 一个元素成员变量 1. private Node head: 记录首结点
2. private int N: 当前栈的元素个数
3. private Node last: 记录最后一个结点成员内部类 private class Node: 节点类
3-6 符号表【第二遍没有实现;MyThird看不太懂;】
3-6-1 符号表
符号表最主要的目的就是将一个键和一个值联系起来,符号表能够存储的数据元素是一个键和一个值共同组成的键值对数据,可以根据键来查找对应的值
- 键具有唯一性
符号表在实际生活中的使用场景很广泛
应用 查找目的 键 值 字典 找到单词的释义 单词 释义 图书索引 找到某个术语相关的页码 术语 一串页码 网络搜索 找到某个关键字对应的网页 关键字 网页名称
- 符号表API设计
类名 Node<key.Value> 构造方法 Node(Key key,Value value,Node next):创建Node对象 成员变量 1. public Key key: 存储键
2. public Value value:存储值
3. public Node next:存储下一个结点符号表:
类名 SymbolTable<Key.Value> 构造方法 SYmbolTable():创建SymbolTable对象 成员方法 1. public Value get(Key key):根据键key,找对应的值
2. public void put(Key key , Value val):想符号表中插入一个键值对
3. public void delete(Key key):删除键为key的键值对
4. public int size(): 获取符号表的大小成员变量 1. private Node head: 记录首结点
2. private int N: 记录符号表中键值对的个数orderSymbolTable.java
3-6-2 有序符号表【MyThird没有做】
3-7 总结:
线性结构:底层的的结构可以是数组(查询快),也可以是线性表(增增删慢)
第五章 树
5-1 二叉树入门+二叉查找树
5-1-1 树的基本定义及相关术语
- 树是我们计算机中非常重要的一种数据结构,
- 树是由n(n<=1)个有限结点组成一个具有层次关系的集合,把它叫做“树”:看起来像倒挂起来的树
- 树具有以下特点:
- 每个结点有零个或多个子节点
- 没有父节点的结点为根节点
- 每一个非根节点只有一个父节点
- 每个节点及其后代节点整体上可以看作一棵树,称为当前结点的父结点的一个子树
- 树的相关术语
- 结点的度: 一个结点含有的子树的个数称为该结点的度
- 叶结点: 度为0的结点称为叶节点,也可以叫做终端结点
- 分支结点: 度不为0的结点称为分支结点,也可以叫做非终端节点
- 终点的层次: 从根结点开始,根节点的层次为1,根的直接后继层次为2,以此类推
- 结点的层序编号:将数中的结点,按照从上层到下层,同层从左到右的次序排成一个线性序列,把他们编成连续的自然数
- 树的度:数中所有结点的度的最大值
- 树的高度(深度):数中结点的最大层次
- 森林:m(m>=0)个互不相交的树的集合,将一颗非空树的根结点删去,树就变化一个森林;给森林增加一个统一的根节点,森林就变成一棵树
- 孩子结点
- 双亲结点(父结点)
- 兄弟结点
5-1-2 二叉树的基本定义:
- 二叉树就是度不超过2的树(每个结点最多有两个子节点)
- 满二叉树:
- 一个二叉树,如果每一个层的结点树都达到最大值,则这个二叉树就是满二叉树
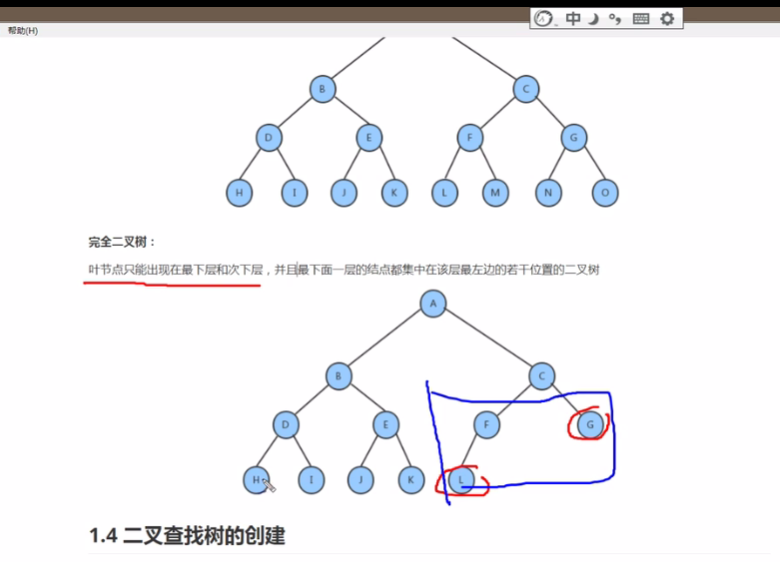
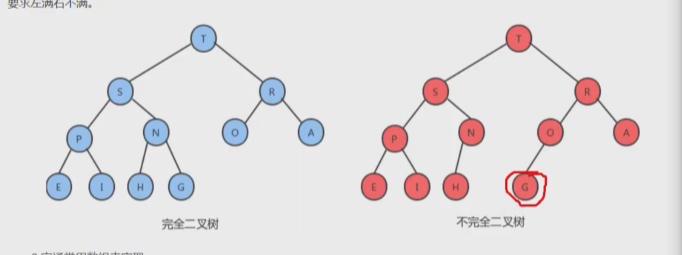
- 完全二叉树:
- 叶结点只能出现在最下层,并且最下面一层的结点都集合在该层最左边的若干位置的二叉树
5-1-3 二叉查找树创建_API设计
二叉树的结点类:
- 根据对图的观察,发现二叉树其实就是由一个一个的结点及其之前的关系组成的,按照面向对象的思想,设计一个结点类来描述结点这个事物
结点类API设计
·类名 Node<Key ,Value> 构造方法 Node(Key key,Value value,Node left,Node right): 创建Node对象 成员变量 1. public Node left:记录左子节点
2. public Node right: 记录右子节点
3. public Key key: 存储键
4. public Value value: 存储值二叉查找树API设计
| 类名 | BinaryTree<Key extends Comparable |
|---|---|
| 构造方法 | BinaryTree():创建BinaryTree对象 |
| 成员变量 | 1.private Node root: 记录根节点 2. private int N: 记录数中元素的个数 |
| 成员方法 | 1. public void put(Key key,Value value):向树中插入一个键值对 2. private Node put(Node x,Key key,Value val): 给指定数x上,添加一个键值对,并返回添加后的新树 3. public Value get(Key key): 根据Key,从树中找出对应的值 4. private Value get(Node x, Key key): 从指定的树x中,找出key对应的值 5. public void delete(Key key):根据key,删除树中对应的键值对 6. private Node delete(Node x,Key key): 删除指定树x上的键位key的键值对,并返回删除后的新树 7. public int size(): 获取树中元素的个数 . |
5-1-4 二叉查找树实现
- 插入方法put实现思想:
- 如果当前树中没有任何一个结点,则直接把新节点当作根节点使用
- 如果当前树不为空,则从根结点开始:
- 如果新结点的key小于当前结点的key,则继续找当前的左子结点
- 如果新结点的key大于当前结点的key,则继续找当前结点的右子节点
- 如果新结点的key等于当前结点的key,则数中已经存在这样的结点,替换该结点的value值即可
5-1-6 二叉树查找_ 查找最大键及查找最小键
最小的键
public Key min() 找出树中最小的键 private Node min(Node x) 找出指定数x中,最小键所在的结点 ```java
//找出整个数中最小的键
public Key min() {return min(root).key;}
// 找出指定树x中最小的键所在的结点
private Node min(Node x) {if(x.left!=null){ return min(x.left); }else { return x; }}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
3. 最大的键
| public Key max() | 找出树中最大的键 |
| ----------------------- | ------------------------------- |
| public Node max(Node x) | 找出指定树x中,最大键所在的结点 |
```java
// 找出整个树中最大的键
public key max(){
return max(root).key;
}
// 找出指定树x中最大键所在的结点
public Node max(Node x){
if(x.right!=null){
return max(x.right);
}else{
return x;
}
}
5-2 遍历【中序和后续有问题】
5-2-1 概述
- 搜索路径:
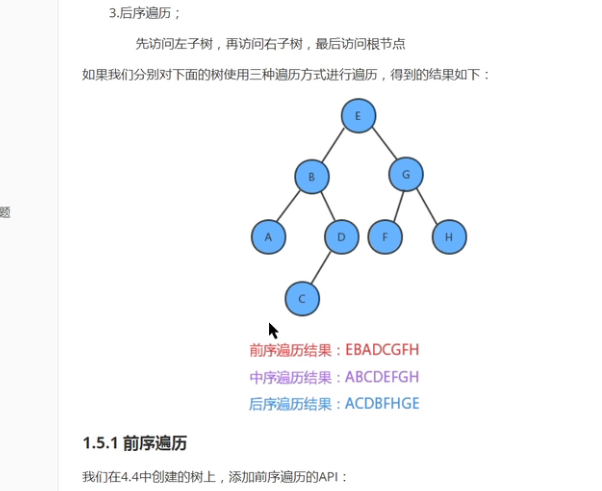
- 前序遍历:
- 先访问根节点,然后再访问左子树,最后访问右子树
- 中序遍历:
- 先访问左子树,中间访问跟结点,最后访问右子树
- 后序遍历:
- 先访问左子树,中间访问右结点,最后访问根子树
- 前序遍历:
5-2-2 前序中序后序遍历的实现
深度遍历
添加前序遍历的API:
public Queue<Key> preErgodic(): 使用前序遍历,获取整个树中的所有键public void preErgodic(Node x,Queue<Key> keys): 使用前序遍历,把指定树x中的所有键放入到keys队列中
实现过程中,可以通过前序遍历,把每个结点的键取出,放入到队列中返回即可
实现步骤:
- 当前节点的key放入到队列中
- 找到当前节点的左子树,如果不为空,递归遍历左子树
- 找到当前节点的右子树,如果不为空,递归遍历右子树
// 使用前序遍历。获取整个树中的所有键 public Queue<Key> preErodic() { Queue<Key> keys = new Queue<>(); preErgodic(root,keys); return keys; } // 使用前序遍历,把指定树x中的所有键放入到keys队列中 private void preErgodic(Node x,Queue<Key> keys){ if(x==null){ return; } //1. 把当前结点的key放入到队列中 keys.enqueue(x.key); }
5-2-2 层序遍历
广度优先
5-3 二叉树的最大深度问题
给定一棵树,计算的树中的最大深度(树的根节点到最远叶子结点的最长路径上的结点数):
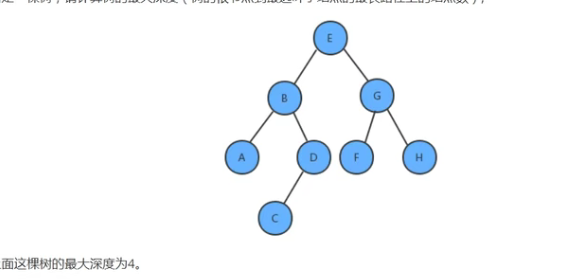
最大深度为4
实现:
- 添加如下的API求最大深度:
public int maxDepth():计算整个树中的最大深度private int maxDepth(Node x):计算指定树x的最大深度
- 添加如下的API求最大深度:
5-4 二叉树_折纸问题
第六章 堆
6-1 堆的概述(层序遍历)
堆的特性:
是完全二叉树,除了树的最后一层结点不需要是满的,其他的每一层从左到右都是满的;
- 如果最后一层结点不是满的,那么要求左满右不满
它通常用数组来实现
具体方法: 将二叉树的结点按照层次顺序放入数组中,根节点在位置1,它的子节点在位置2和3,而子结点的子结点则分别在位置4,5,6,7
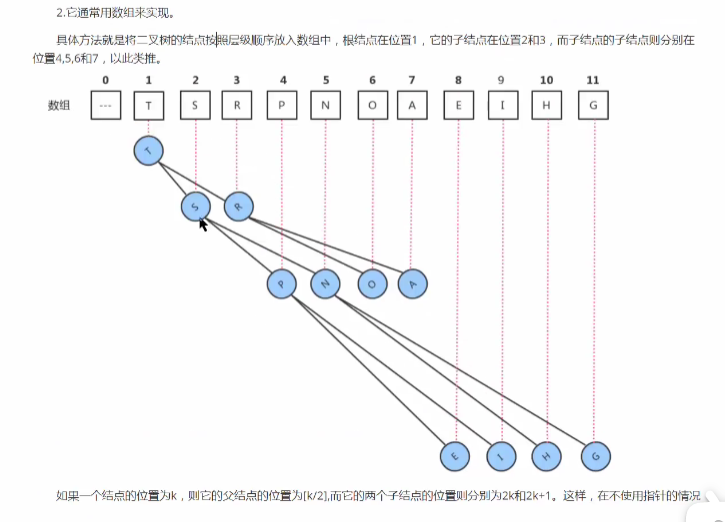
如果一个结点的位置为k,则它的父结点为
[k/2],而它的两个子结点的位置则分别为2k和2k+1,在不使用指针的情况下,可以通过数组的索引在树中上下移动;从a[k]向上一层,就令k = k/2,向下一层就令k = 2k或2k+1
每个结点都大于等于它的两个子结点;堆中规定了每个结点大于等于它的两个子结点,但这两个子结点的顺序并没有做规定
6-2 堆的API设计
堆的底层实现是数组
类名 Heap<T extends Comparable > 构造方法 Heap(int capacity): 创建容量为capacity的Heap对象 成员方法 1. private boolean less(int, int j): 判断堆中索引i处的元素是否小于索引j处的元素
2. private void exch(int i,int j): 交换堆中索引i和索引j处的值
3. public T delMax():删除堆中最大的元素,并返回这个最大元素
4. public void insert(T t): 往堆中插入一个元素
5. private void swim(int k): 使用上浮算法,使索引k处的元素能在堆中处在一个正确的位置
6. private void sink(int k): 使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置成员变量 1. private T[] items: 用来存储元素的数组
2. private int N: 记录堆中元素的个数
6-3 堆的实现【Mywrite删除有一丢丢懵,思路明白,代码绕,测试结果有问题;】
insert插入方法的实现
- 堆是用数组完成数据元素的存储的,由于数组的底层是一串连续的内存地址
- 所以我们往堆中插入数据,只能往数组中从索引0处开始,依次往后存放数据
- 但是堆中对元素的顺序有要求,每一个结点的数据要>= 它的两个子结点的数据,所以每次插入一个元素,都会使得堆中的元素数据变乱
- 通过方法让刚才插入的数据放在合适的位置
堆上浮的一个过程:
往堆中新插入元素,只需要不断的比较新结点a[k]和它的父结点a[k/2]的大小,根据结果完后数据元素的交换,可以完成堆的有序调整
堆的删除:
6-8 堆的排序
数组:
String[] arr = {"S","O","A","F"}- 将数组中的字符从小到大排序
API设计:
类名 HeapSort<T extends Comparable > 成员方法 1. public static void sort(Comparable[] source):对source数组中的数据从小到大排序
2、private static void createHeap(Comparable[] source,Comparable[] heap):根据原数组source,构造出堆heap
3.private static boolean less(Comparable[] heap,int i, int j ): 判断heap堆中索引i处的元素是否小于索引j处的元素
4.private static void exch(Comparable[] heap,int i , int j): 交换heap堆中i索引和j索引处的值
5.private static void sink(Comparable[] heap,int target,int range): 在heap堆中,对target处的元素做下沉,范围是0-range堆构造过程:
- 方法一 : 堆的构造,最直观的想法就是另外再创建一个新数组,然后从左往右遍历原数组,每得到一个元素,添加到新数组中,并通过上浮,对堆进行调整,最后的新数组就是一个堆
- 方法二:创建一个新数组,把原数组0-length-1的数据拷贝到新数组的1-length处,再从新数组长度一半处开始往1索引处扫描(从右往左),然后对扫描到的每一个元素做下沉调整即可
第6-一章 优先队列(堆)
6-1 优先队列
- 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。
- 在某些情况下,需要找出队列中的最大值或者最小值,例如使用一个队列保存计算机的任务,一般情况下计算机的任务都是有优先级的
- 需要在这些计算机的任务中找出优先级最高的任务先执行,执行完毕后需要把这个任务从队列中移除。
- 普通的队列需要每次遍历队列中的所有元素,比较并找出最大值,效率不高,可以使用一种特殊的队列来完成功能,优先队列
优先队列按照起作用不同,可以分为:
- 最大优先队列
- 可以获取并删除队列中最大的值
- 最小有限队列
- 可以获取并删除队列中最小的值=

- 最大优先队列
6-2 最大优先队列
最大优先队列API设计
类名 MaxPriorityQueue<T extends Comparabke > 构造方法 MaxPriorityQueue(int capacity): 创建容量为capacity 的 MaxPriorityQueue 对象 成员方法 1. private boolean less(int i, int j): 判断堆中索引i处的元素是否校园索引j处的元素
2. private void exch(int i,int j):交换堆中i索引和j索引处的值
3. public T delMax(): 删除队列中最大的元素,并返回这个最大元素
4. public void insert(T t): 往队列中插入一个元素
5. private void swim (int k): 使用上浮算法,使索引k处的元素能在堆中处于 一个正确的位置
6. private void sink(int k): 使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置
7. public int size(): 获取队列中元素的个数
8. public boolean isEmpty():判断队列是否为为空成员变量 1. private T[] imtes:用来存储元素的数组
2. private int N: 记录堆中元素的个数
第七章 平衡树
7-1 查找树
7-1-1 查找树_概述
7-1-2 查找树的定义:
- 2-结点: 含有一个键(及其对应的值)和两条链,左链接指向2-3数中的键都小于该结点,右链接指向 的2-3 数中的键都大于该结点
- 3- 结点: 含有两个键(及其对应的值)和三条链,左链接指向的2-3树中的键都小于该结点,中链接指向的2-3 树中的键都位于该结点的两个键之间,右链接指向的2-3 数中的键都大于该结点
7-1-3 插入
- 向2-结点中插入新键
- 向一棵树只含有一个3-结点的数中插入新键
- 像一个父结点为2- 结点的3-结点中插入新键
7-1-4 2-3树的性质
- 2-3 树需要做一些局部的变换来保持2-3树的平衡
- 完全平衡的2-3树的性质:
- 任意空链接到根结点的路径长度都是相等的
- 4-结点变换为3-节点时,树的高度不会变化,只有当根节点是临时的4-结点,分解根节点时,树高+1
- 2-3树与普通二叉查树做大得到区别在于,普通的二叉查找树是自顶向下生长的,而2-3树
7-2 红黑树
7-2-1 定义
- 前面介绍了2-3树,可以看到2-3 树能保证在插入元素之后,树依旧保持平衡状态,最坏情况下所有子结点都是2-结点,树的高度为lgN
- 相比于普通的二叉查找树,最坏情况下树的高度为N,确实保证了最坏情况下的时间复杂度,但是2-3树实现起来过于复杂
- 介绍一种2-3树思想的简单实现: 红黑树
- 红黑树主要是对2-3 树进行编码,红黑树背后的基本思想是用标准的二叉查找树(完全由2-结点构成)和一些额外的信息(替换3-结点)来表示2-3树
- 红链接; 将两个2-结点连接起来构成一个3-结点
- 黑链接: 则是2-3 数中的普通链接
- 将3- 结点表示为由一条左斜的红色链接(两个2-结点,其中之一是另一个的左子节点)相连的两个2-结点;表示的优点-无需修改就可以直接使用标准的二叉查找树的get方法

7-2-2 红黑树结点树API
每个结点
类名 Node<Key,Value> 构造方法 Node(key key,Value value,Node left,Node right,boolean color): 创建Node对象 成员变量 1. public Node left: 记录左子结点
2. public Node right:j记录右子结点
3. public Key key: 存储键
4. public Value value: 存储点
5. public boolean color: 由其父结点指向它的链接的颜色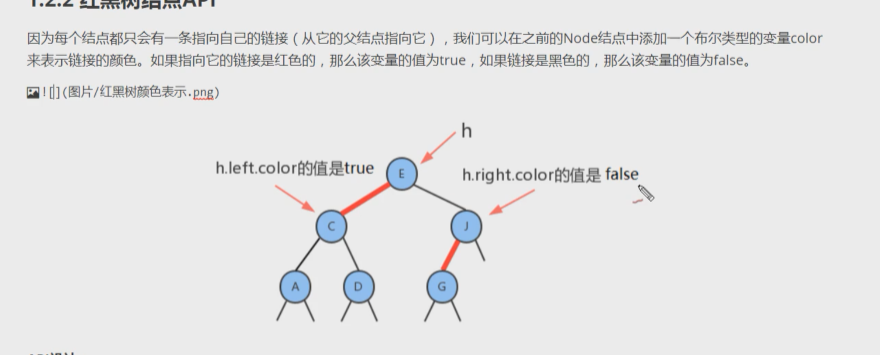
7-2-3 平衡化
在对红黑树进行一些增删改查的操作后很有可能会出现红色的右链接或者两条连续红色的链接,而这些都不满足红黑树的定义,多以我们需要对这些情况进行修复
- 左旋:
- 让x的左子结点变为h的右子结点: h.right = x.left;
- 让h成为x的左子节点: x.left = h;
- 让h的color属性变为x的color属性值: x.color = h.color;
- 让h的color属性变为RED : h.color = true;
- 左旋
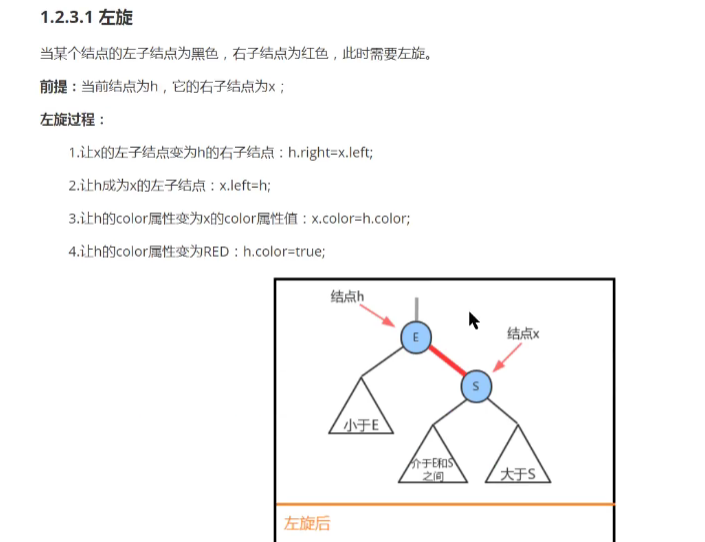
- 右旋
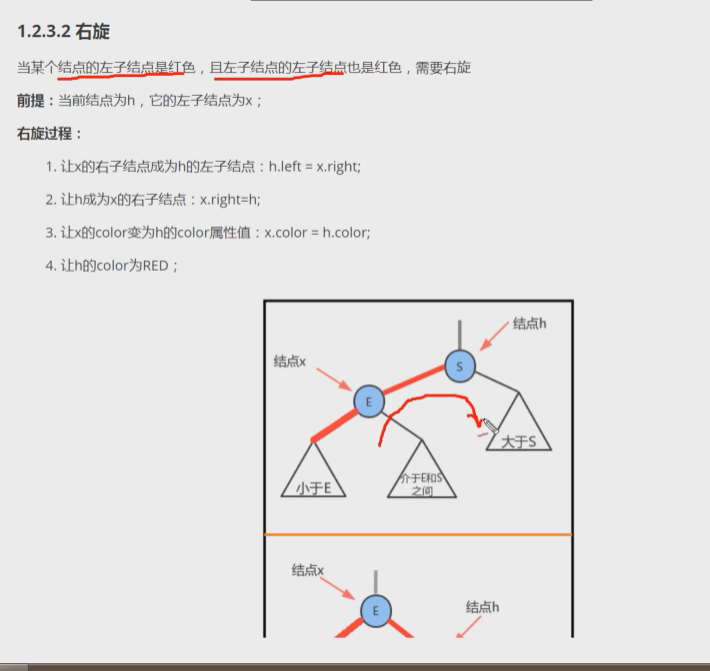
7-3 红黑树的插入
7-3-1 向单个2-结点中插入新键
7-3-2 向底部的2-结点插入新建
7-3-3 颜色反转
7-3-4 向一棵双键树(即一个3-结点)中插入新键
7-3-5 根节点的颜色总是黑色
7-3-6 向根底部的3-结点插入新键
7-3-7 红黑树的API设计
类名 RedBlackTree<Key extends comparable , value> 构造方法 RedBlackTree():创建RedBlackTree对象 成员方法 1.private boolean isRed(Node x):判断当前结点的父指向链接是否为红色
2.private Node rotateLeft(Node h):左旋调整
3.private Node rotateRight(Node h):右旋调整
4.private void flipcolors(Node h):颜色反转,相当于完成拆分4-结点
5.public void put(Key key, value val):在整个树上完成插入操作
6.private Node put(Node h, Key key, Value val):在指定树中,完成插入操作,并返回添加元素后新的树
7.public value get(Key key):根据key ,从树中找出对应的值
8.private Value get(Node x, Key key):从指定的树x中,找出key对应的值
9.public int size():获取树中元素的个数成员变量 1.private Node root : 记录根结点
2.private int N:记录树中元素的个数
3.private static final boolean RED:红色链接标识
4.private static final boolean BLACK:黑色链接标识
7-3-8 红黑树的实现
第八章 图
8-1 图的简介
- 地图: 把城市看作一个个点,道路看作一条条连接,地图就就是要学习的图
- 图: 是由一组顶点和一组能够将两个顶点相连的边组成
- 图的分类:(按照连接两个顶点的边的不同)
- 无向图: 边仅仅连接两个顶点,没有其他含义
- 有向图:边不仅连接两个顶点,并且具有方向
- 特殊的图:
- 自环: 即一条连接一个顶点和其自身的边
- 平行边: 连接同一对顶点的两条边
8-2 图的相关术语:
- 相邻顶点:当两个顶点通过一条边相连时,称这两个顶点相邻,并且称这条边依附于这两个顶点
- 度: 某个顶点的度就是依附于该顶点的边的个数
- 子图: 是一幅图的所有边的子集(包含这些依附的顶点)组成的图
- 路径: 是由边顺序连接的一系列的顶点组成
- 环: 是一条至少含有一条边终点和起点相同的路径
- 连接图: 如果图中任意一个顶点都存在一条路径到达两外一个顶点,那么这幅图就称之为连接图
- 连接子图: 一个非连接图由若干连接部分组成,每一个连接的部分都可以称为该图的连接子图
8-3 图的存储结构
要表示一幅图,只需要表示清楚:
- 图中所有的顶点
- 所有连接顶点的边
常见的图的存储结构有两种: 邻接矩阵和邻接表
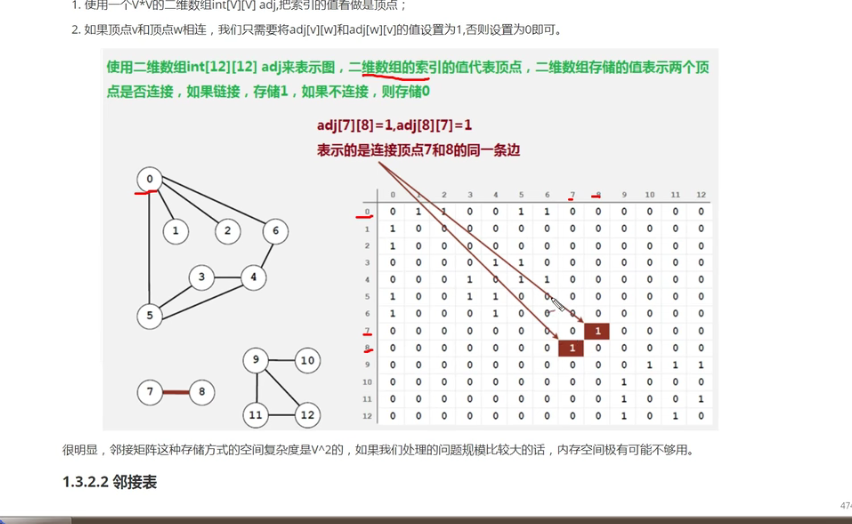
8-3-1 邻接矩阵
- 使用一个
V*V的二维数组int[V][V] adj,把索引的值看作顶点 - 如果顶点v和顶点w相连,只需要将
adj[v][w]和adj[w][v]的值设置为1,否则设置为0即可 - 很明显,邻接矩阵的存储方式的空间复杂度是
V^2,如果规模较大的话,内存空间可能不够用
8-3-2 邻接表
使用一个大小为V的数组
Queue[V] adj, 把索引看作是顶点每个索引处
adj[v]存储一个队列,该队列中存储的是所有与该顶点相邻的其他顶点邻接表的空间并不是线性级别的,所以我们一直采用邻接表这种存储方式来表示图
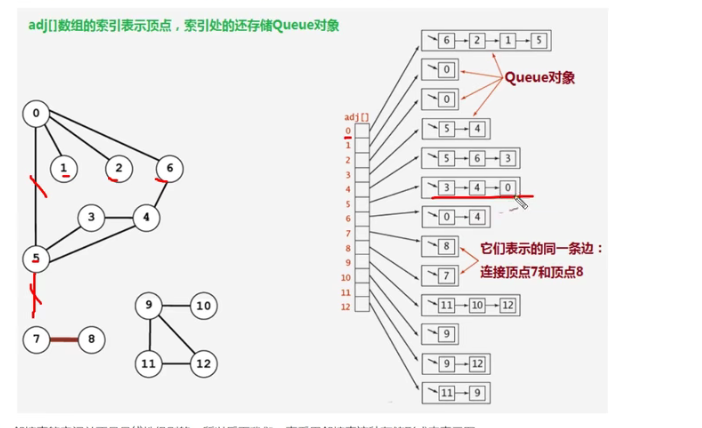
8-3-3 图的API设计
类名 Graph 构造方法 Graph(int v): 创建一个包含V个顶点但不包含边的图 成员方法 1. public int V(): 获取图中顶点的数量
2.public int E(): 获取图中边的数量
3,public void addEdge( int v,int w): 向图中添加一条边v-w
4.public Queue<integer>adj(int v): 获取和顶点v相邻的所有顶点成员变量 1. private final int V: 记录顶点数量
2.private int E: 记录边数量
3.private Queue<Integer>[] adj: 邻接表
8-无向图
8-4 图的搜索
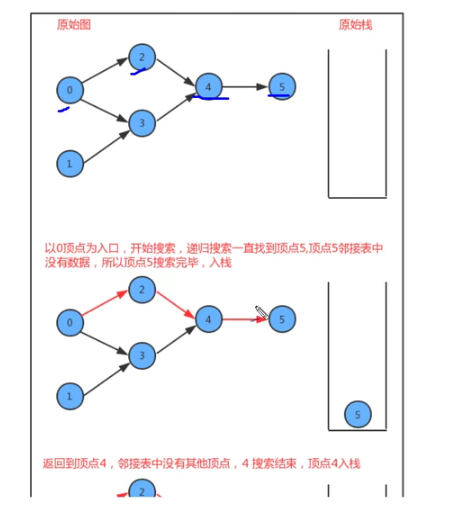
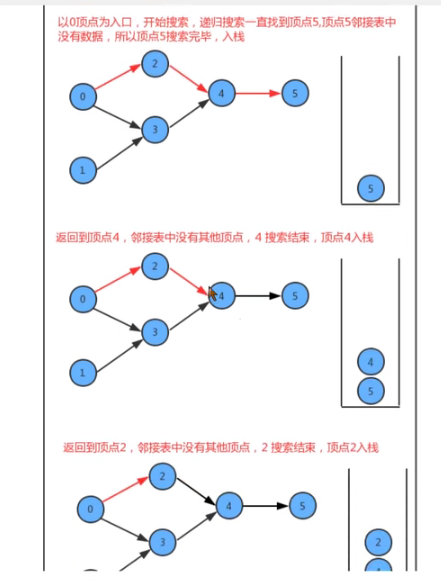
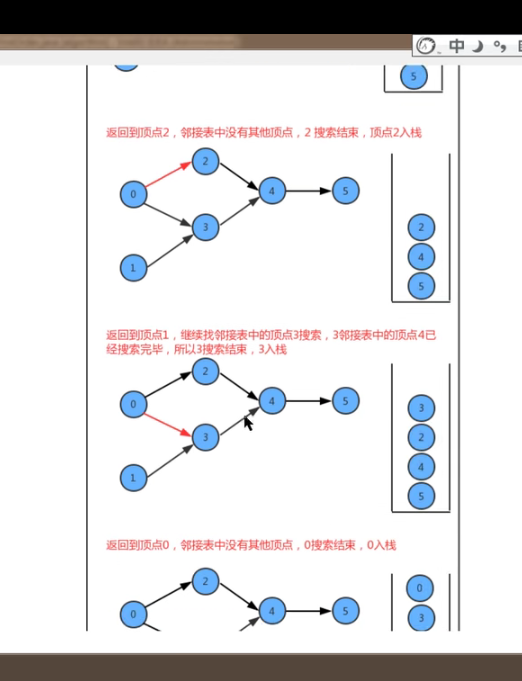
8-4-1 深度优先搜索 – 实现【mywrite看不懂,没理解深层意思;】
深度优先搜索:遇到一个结点既有子结点,又有兄弟节点,那么先找子结点,再找兄弟节点
类名 DepthFirstSearch 构造方法 DepthFirstSearch(Graph G,int s): 构造深度优先搜索对象,使用深度有线索搜索找出G图中s顶点的所有相通顶点 成员方法 1. private void dfs(Graph G, int v) : 使用深度优先搜索找出G图中v顶点的所有相通顶点
2. public boolean marked(int w): 判断w顶点与s顶点是否相通
3. public int count() : 获取与顶带s相通的所有顶点的总数成员变量 1. private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索
2. private int count: 记录有多少个顶点与s顶点相通
8-4-2 广度优先搜索(层序遍历 )
所谓的深度优先搜索,指的是在搜索时,遇到一个结点既有子结点,又有兄弟结点,那么先找兄弟结点,然后再找子结点
API设计:
类名 BreadthFirstSearch 构造方法 BreadFirstSearch(Graph G, int s): 构造广度优先搜索对象,使用广度优先搜索找出G图中的所有相邻顶点 成员方法 1. private void dfs(Graph G, int v) : 使用深度优先搜索找出G图中v顶带你的所有相通顶点
2. public boolean marked(int w): 判断w顶点与s顶点是否相通
3. public int count() : 获取与顶带s相通的所有顶点的总数成员变量 1. private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索
2. private int count: 记录有多少个顶点与s顶点相通
3. private QueuewaitSearch: 用来存储待搜索邻接表的点
8-8 案例 – 畅通工程续【没写进去Mywrite】
8-5 路径查找【读不到文件呀!!!】
8-5-1 路径查找API设计
类名 DepthFirstPaths 构造方法 DepthFirstPaths(Graph G,int s): 构造深度优先搜索对象,使用深度优先搜索找出G图中起点为s的所有路径 成员方法 1. private void dfs(Graph G, int v) : 使用深度优先搜索找出G图中v顶带的所有相邻顶点
2. public boolean hasPathTo(int v): 判断v顶点与s顶点是否存在路径
3. public StackpathTo(int v) : 找出从起点s到顶点v路径(就是改路径经过的顶点) 成员变量 1. private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索
2. private int s:起点
3. private int[] edgeTo: 索引代表顶点,值代表从起点s到当前顶点路径上的最后一个顶点
8-有向图
8-6 有向图
8-6-1 有向图的定义和相关术语
- 定义: 有向图是一幅有方向性的图,是一组顶点和一组有方向的边组成的,每天方向的边都连着一对有序的顶点
- 出度 : 由某个顶点指出的边的个数称为该顶点的出度
- 入度: 指向某个顶点的边的个数称为该顶点的入度
- 有向路径: 由一系列顶点组成,对于其中的每个顶点都存在一条有向边,从它指向序列的下一个顶点
- 有向环: 一条至少含有一条边,且起点和终点相同的有向路径
- 一副有向图中两个顶点v和w可能存在以下四种关系:
- 没有边相连
- 存在从v到w的边:
v ---》 w - 存在从w到v的边:
w ---> v - 既存在w到v的边,也存在v到w的边,即双向连接】
8-6-2 有向图API设计:
类名 Digraph 构造方法 Graph(int v): 创建一个包含V个顶点但不包含边的图 成员方法 1. public int V(): 获取图中顶点的数量
2.public int E(): 获取图中边的数量
3,public void addEdge( int v,int w): 向图中添加一条边v->w
4.public Queue<integer> adj(int v): 获取由v指出的边所连接的所有顶点
5.private Digraph reverse(): 该图的反向图成员变量 1. private final int V: 记录顶点数量
2.private int E: 记录边数量
3.private Queue<Integer>[] adj: 邻接表在api中设计了一个反向图,其因为有向图的实现中,用adj方法获取出来的是由当前顶点指向的其他顶点,如果能得到其反向图,就可以得到指向v的其他顶点
8-7 图——拓扑排序
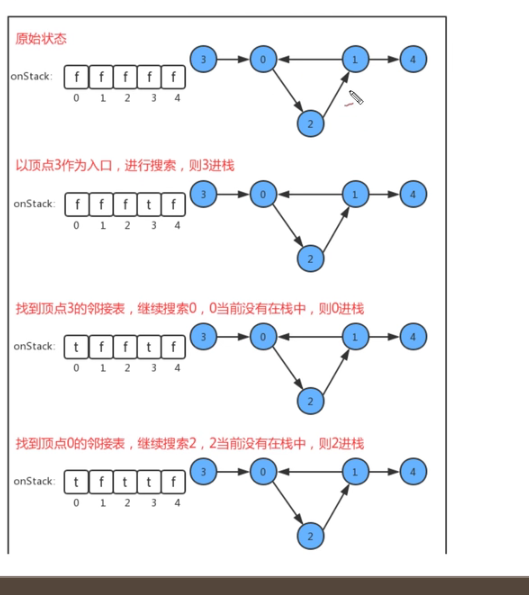
8-7-1 概述 + 检测有向图中的环
拓扑排序: 给定一幅有向图,将所有的顶点排序,使得所有的有向边均从排在前面的元素指向排在后面的元素,此时就可以明确表示出每个顶点的优先级。一幅拓扑排序后的示意图:
检测有向图中的环:
API设计:
·类名 DirectedCycle 构造方法 DirectedCycle(Digraph G): 创建一个检测环对象,检测图G中环是否有环 成员方法 1. private void dfs(Digraph G, int v): 基于深度优先搜索,检测图G中是否有环
2. public boolean hasCycle(): 检测图中是否有环成员变量 1. private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索
2. private boolean hasCycle: 记录途中是否有环
3. private boolean[] onStack: 索引代表顶点,使用栈的思想,记录顶点有没有已经处于正在搜索的有向路径上
8-7-2 基于深度优先的顶点排序
顶点API设计
类名 DepthFirstOrder 构造方法 DepthFirstOrder(Digraph G) : 创建一个顶点排序对象, 生成顶点线性序列 成员方法 1. private void dfs(Digraph G, int v): 基于深度优先搜索,生成顶点线性序列
2. public StackreversePost():获取顶点线性序列 成员变量 1。 private boolean[] marked: 索引代表顶点,值 表示当前顶点是否已经被搜索
2. private StackrevesePost: 使用栈,存储顶点序列
在API设计中,添加一个栈reversePost用来存储顶点,深度搜索图是,每搜索完毕一个顶点,把该顶点放入到
reversePost中,就可以实现顶点序列